🚨 The story in 2 minutes
When a real tech company has an outage, three people's phones
buzz at once — a Triage engineer, an Investigator, and an Ops
Manager. They have to cooperate under a ticking SLA clock,
every action costs budget, and every wrong call costs
real money (enterprise outages hurt ~3× more than free-tier).
We built a simulator of that war room — and we fine-tuned an LLM to run it
as well as the human expert.
What is the environment?
Three specialist agents with different permissions resolve a live queue of 13 realistic tech incidents across 3 difficulty tiers.
| Role | Can do | Cannot do |
|---|---|---|
| 🔍 Triage | Pull logs · check metrics · consult KB | Close a ticket |
| 🧪 Investigator | Apply a fix · roll back a deploy | Escalate or file a post-mortem |
| 👷 Ops Manager | Escalate · file post-mortem · close the ticket | Apply a code fix |
What did the agent learn?
Not "pick the right label." It learned a whole workflow — dig up clues, hand off to the right specialist, apply the correct fix, respect the SLA, file the post-mortem, close the ticket. The rubric makes every piece of that workflow visible as a named reward component, so you can see why the agent earned (or lost) points at every step.
Why it matters for the 3 hackathon themes
🤝 Theme #1 — Multi-Agent
Three distinct roles with non-overlapping permissions.
Wrong-actor calls → -0.08. Correct handoff → +0.15.
Cooperation is trained, not hard-coded.
⏱️ Theme #2 — Long-Horizon
Each episode runs 3–5 sequential incidents over 20–60 steps with a single ticking SLA clock. Big rewards (+0.80 × tier) only fire after clues → fix → post-mortem. Sparse and delayed by design.
🏢 Theme #3 — Professional World-Model
Real logs, metrics, KB articles, red-herring signals, customer tiers, SLA timers, revenue impact. Close an enterprise ticket wrong and it hurts ~3× what a free-tier one does.
↓ Keep scrolling for the headline numbers, training plots, ablation, and the full rubric. Or jump straight to the README or the blog post.
Resources & documentation
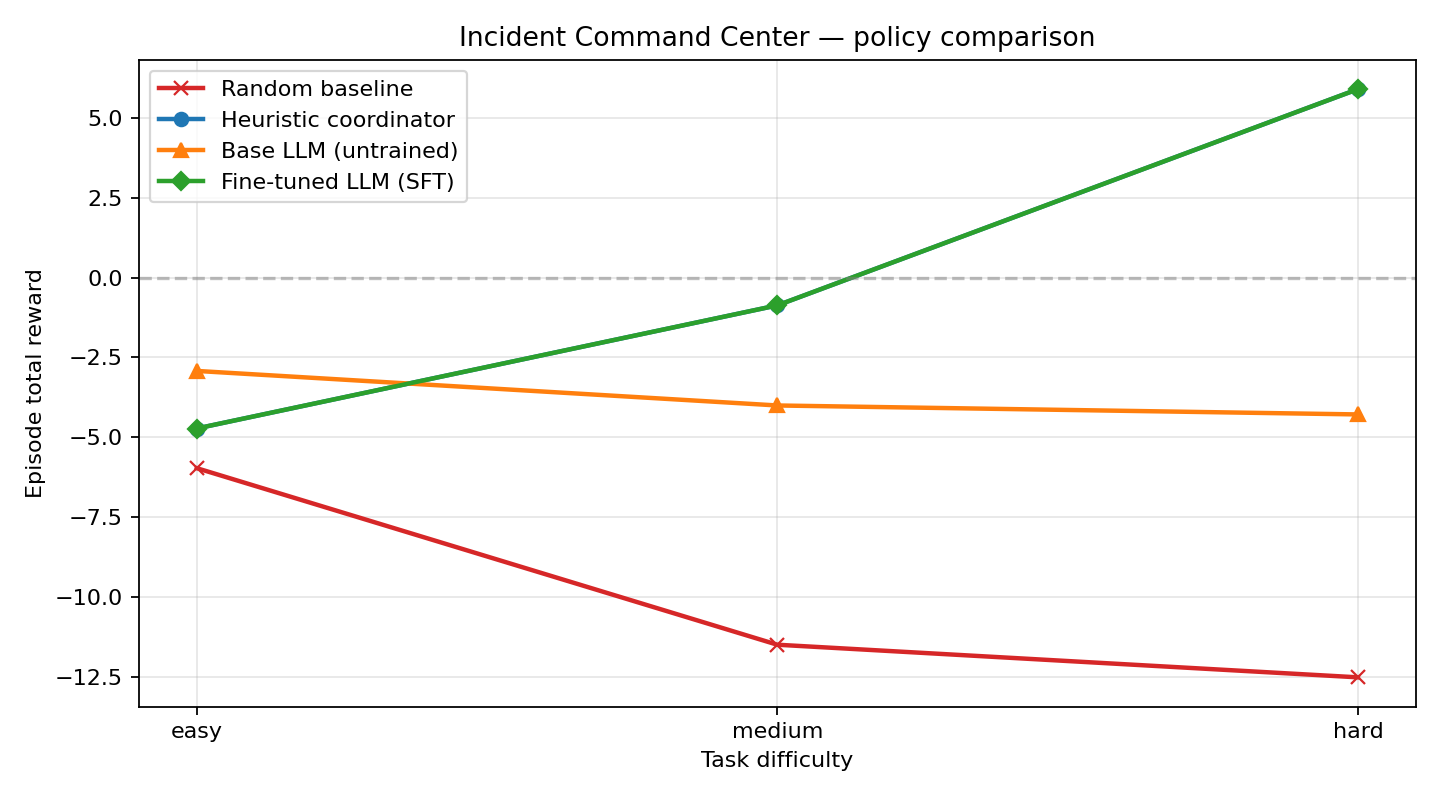
Headline results
Environment at a glance
1.5B SFT vs base (reference run)
| Task tier | Base reward | SFT reward | Δ |
|---|---|---|---|
| easy | -2.92 | -4.72 | -1.80 |
| medium | -4.00 | -0.87 | +3.13 |
| hard | -4.28 | +5.89 | +10.17 |
Numbers loaded live from summary_metrics.json committed alongside this Space.
Training evidence
Committed artifacts from the reference training run (Qwen2.5-1.5B-Instruct, 8 episodes/task, 3 epochs) plus the Qwen2.5-0.5B-Instruct ablation. Click any plot to open it full-size.
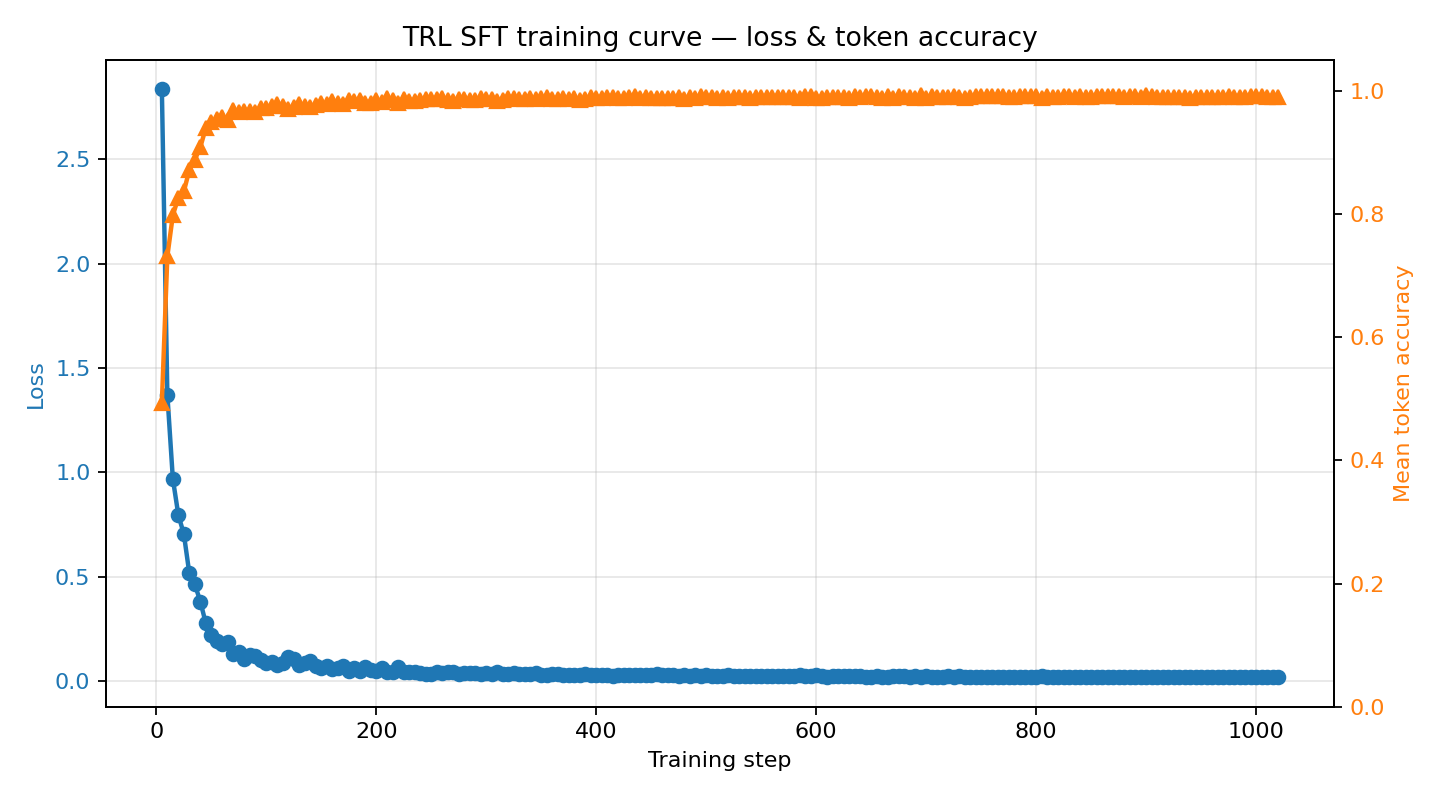
~2.84 → ~0.02 and next-token accuracy climbs from
~0.49 → ~0.99 over three epochs on 680 rollout tokens.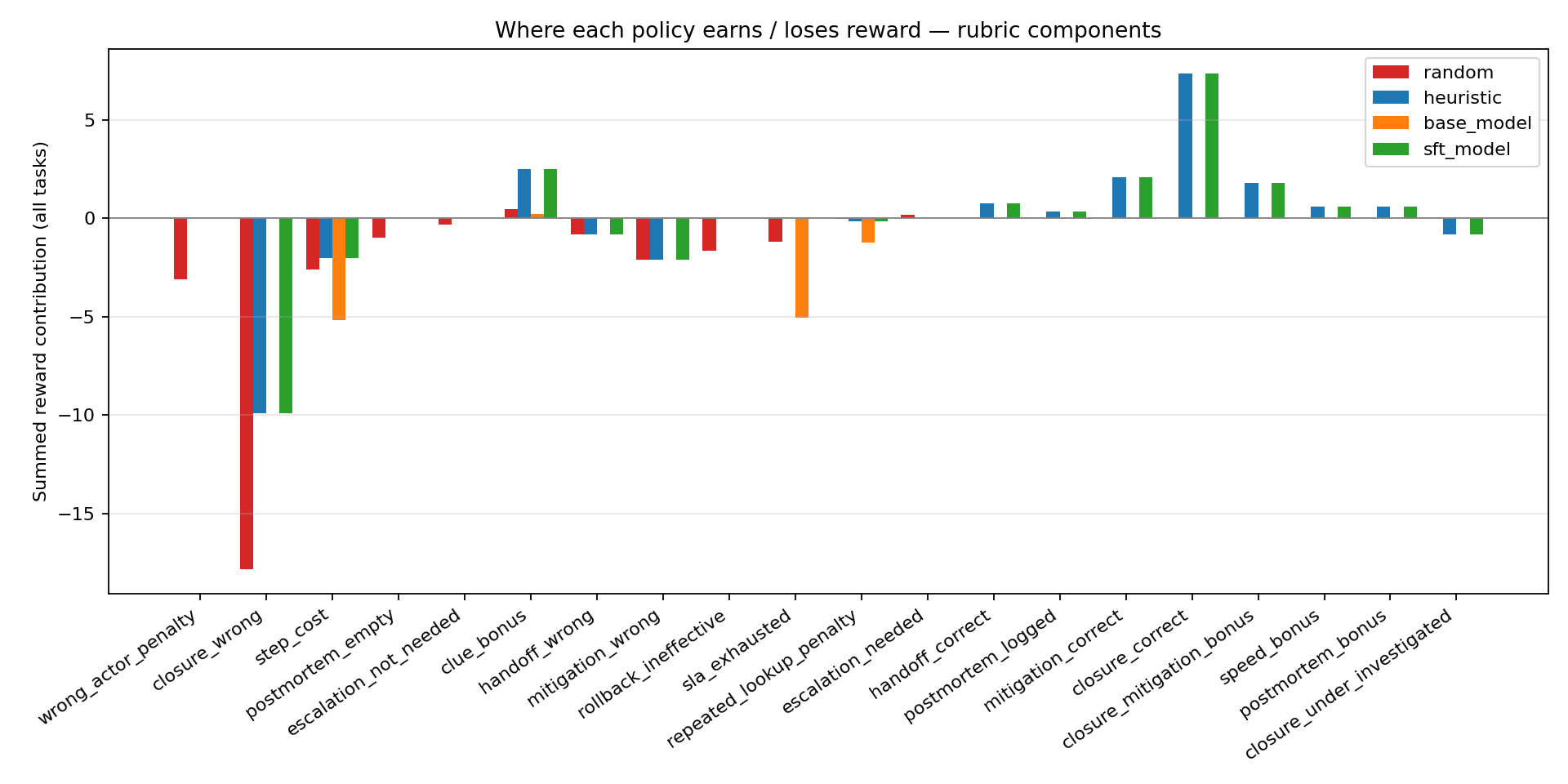
clue_bonus,
mitigation_correct, closure_correct,
speed_bonus) while the base model stalls on
step_cost and SLA penalties.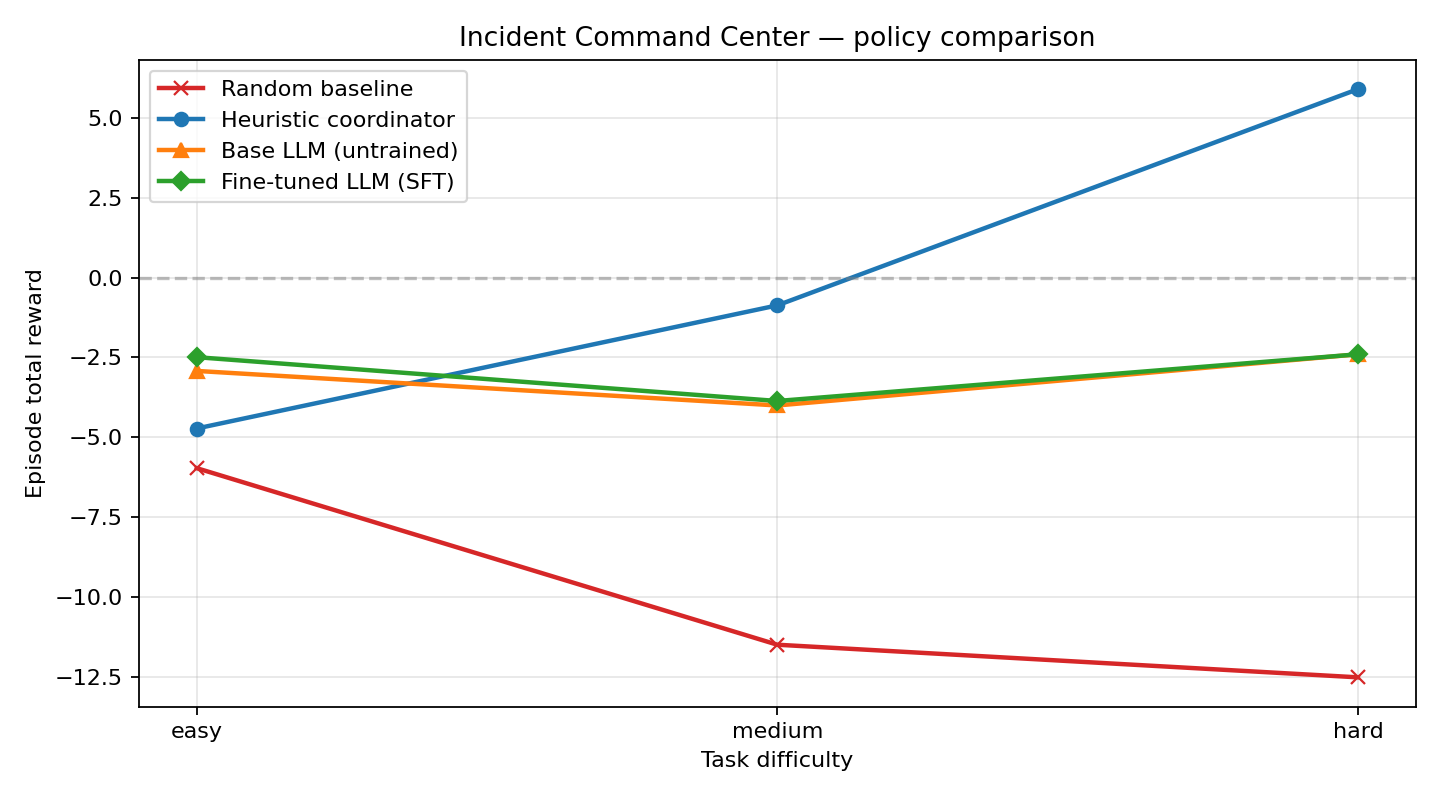
Raw files: summary_metrics.json · training_log.json · summary_metrics_qwen0p5b.json
Ablation: model scale matters for imitation learning
Same pipeline, same data schema — only the base-model size differs. The 0.5B model cannot absorb the expert policy; 1.5B matches it exactly.
| Model | Easy Δ | Medium Δ | Hard Δ | Heuristic match? |
|---|---|---|---|---|
| Qwen2.5-0.5B-Instruct | +0.43 | +0.14 | +0.00 | No (stuck on step-cost) |
| Qwen2.5-1.5B-Instruct | -1.80 | +3.13 | +10.17 | Yes (exact match) |
Endpoints
Standard OpenEnv contract plus operational endpoints.
POST /reset— start a new episode (task_name, seed).POST /step— submit an IncidentAction.GET /state— full environment state.GET /healthz— liveness probe.GET /version— build information.GET /env-info— action space, reward model, budgets.GET /metrics— Prometheus-style counters.GET /docs— interactive OpenAPI documentation.GET /artifacts/…— committed training plots & metrics.
Action space
Each action is gated by the acting role; wrong-actor calls are penalised.
Reward model
Composable rubric with anti-gaming safeguards. Every step returns a
reward_components dictionary so training curves are
interpretable. Closure rewards and SLA penalties are scaled by
customer-tier multipliers:
free: x0.6standard: x1.0premium: x1.4enterprise: x1.8
| Component | Signal |
|---|---|
step_cost | -0.04 per investigation step |
clue_reward | +0.12 per new fact |
handoff_correct | +0.15 |
mitigation_correct | +0.35 |
closure_correct_base | +0.8 × tier multiplier |
closure_wrong | -1.1 × tier multiplier |
Full rubric (invalid-action, repeated-lookup, rollback-effective, post-mortem-logged, etc.) is documented in the README.
Metadata
{
"name": "incident_command_center_env",
"version": "3.0.0",
"tasks": [
"easy",
"medium",
"hard"
],
"incidents_per_task": {
"easy": 3,
"medium": 5,
"hard": 5
},
"actions": [
"inspect_logs",
"inspect_metrics",
"consult_kb",
"negotiate_handoff",
"apply_fix",
"close_incident",
"escalate",
"rollback",
"submit_postmortem"
],
"roles": [
"triage_agent",
"investigator_agent",
"ops_manager_agent"
],
"reward_model": {
"step_cost_investigation": -0.04,
"clue_reward": 0.12,
"handoff_correct": 0.15,
"mitigation_correct": 0.35,
"closure_correct_base": 0.8,
"closure_wrong": -1.1,
"tier_multiplier": {
"free": 0.6,
"standard": 1.0,
"premium": 1.4,
"enterprise": 1.8
}
},
"budgets": {
"easy": 28,
"medium": 54,
"hard": 84
},
"sla_minutes": {
"easy": 120,
"medium": 210,
"hard": 330
}
}